Support Vector Machines
At this point we have seen a number of learning algorithm. While it is true to a certain degree that different learning algorithms have similar performances and that the amount and quality of data is fundamental, we need to cover another class of learning algorithm that are often used in industry and academia, the Support Vector Machines (SVM). These algorithms can sometimes give a cleaner and more powerful way of learning complex non-linear functions.
Optimization objective
Let’s see how we can get to a support vector machine from a logistic regression algorithm.
In a classic logistic regression algorithm we have our hypothesis based on the sigmoid activation function
\[h_\theta(x) = \frac{1}{1+e^{-\theta^Tx}}\]
In logistic regression:
- for $y=1$ we would like $h_\theta(x)\approx 1 \leftarrow \theta^T \gg 0$
- for $y=0$ we would like $h_\theta(x)\approx 0 \leftarrow \theta^T \ll 0$
Each examples contributes to the total cost computed by the cost function by the term:
\[-y \log (h_\theta(x)) - (1-y) \cdot \log (1-h_\theta(x))\]That, when replacing the $h_\theta(x)$ term, becomes:
\[\begin{equation} \color{royalblue}{-y\log \left(\frac{1}{1+e^{-\theta^Tx}}\right)} - \color{darkgreen}{(1-y) \cdot \log \left(1-\frac{1}{1+e^{-\theta^Tx}} \right)} \end{equation} \label{eq:logcost} \tag{1}\]When $y=1$, the contribution to the cost function is given by the left factor in $\eqref{eq:logcost}$, a single example will have a very small contribution to the cost function for large values of $z$ (Figure 17. As we will see later, this make the SVM behave similarly to logistic regression while giving a computational advantage by simplifying the optimization problem.
When $y=0$, the SVM will be very similar with a semi-step behavior at 1 in reversed direction (Figure 17, panel B, orange line)
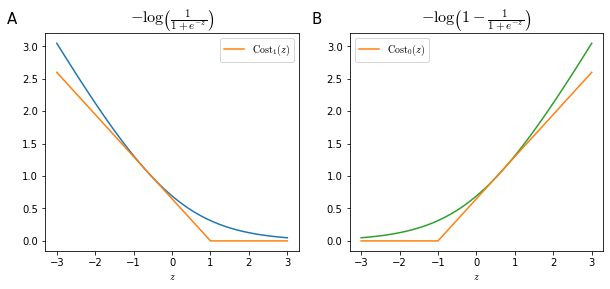
So, where the optimization problem in logistic regression is:
\[\min_\theta\frac{1}{m} \sum_{i=1}^m \left[y^{(i)} \left(- \log h_\theta(x^{(i)})\right) +(1-y^{(i)}) \cdot \left(-\log (1-h_\theta(x^{(i)}))\right) \right] + \frac{\lambda}{2m} \sum_{j=0}^n\theta_j^2\]By just substituting the $Cost_{0/1}$ terms, the optimization problem for an SVM would be:
\[\begin{equation} \min_\theta \color{red} {\frac{1}{m}} \color{black}{\sum_{i=1}^m \left[ y^{(i)} \text{ Cost}_1(\theta^Tx^{(i)}) + (1-y^{(i)}) \text{ Cost}_0(\theta^Tx^{(i)}) \right] +} \frac{ \color{magenta}{ \lambda}}{2 \color{red}{m}} \sum_{j=0}^n\theta_j^2 \end{equation}\]However we are going to slightly reparametrize it:
- First we are going to get rid for the $\color{red}{\frac{1}{m}}$ term, as for the SVM the convention doesn’t include this term. Since this term is a constant, we should end up with the same optimal value for $\theta$ if we either include or remove it.
- Second, we want to remove the regularization parameter $\color{magenta}{\lambda}$ in favor of another parameter that we can call $\color{magenta}{C}$. While in logistic regression we express the optimization problem in the form $A+\lambda B$, in SVM the form is $CA+B$, where $C$ can be thought as (but is not equivalent to) $\frac{1}{\lambda}$, in the sense that reducing $C$ has the effect of scaling down $A$ with respect to $B$.
With these two modifications we can now write the conventional form of the optimization problem for an SVM:
\[\begin{equation} \min_\theta C \sum_{i=1}^m \left[y^{(i)} \text{ Cost}_1(\theta^Tx^{(i)}) + (1-y^{(i)}) \text{ Cost}_0(\theta^Tx^{(i)}) \right] + \frac{1}{2} \sum_{j=0}^n\theta_j^2 \end{equation} \label{eq:svmcost} \tag{2}\]Large Margin Classification
Sometimes SVMs are referred to as large margin classifiers. In this section we will see why and we will introduce the hypothesis representation of SVMs.
Large margin classification - intuition
By looking at Figure 18, we can see that if we want to minimize the cost of a training example, we need to have:
- If we have $y=1$ (panel A), then to have $\text{Cost}_1(z)=0$, we need to have $z \equiv (\theta^Tx) \geq 1$ and not just $\geq 0$
- If we have $y=0$ (panel B), then to have $\text{Cost}_1(z)=0$, we need to have $z \equiv (\theta^Tx) \leq -1$ and not just $< 0$
This builds in an extra safety margin for correct classification in SVMs.
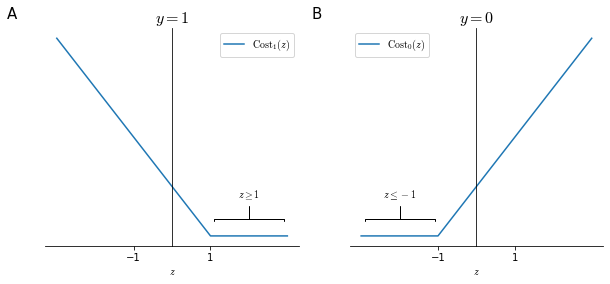
Consider a case where we set the regularization parameter $C$ to a very large value. This will allow us to see a simplified and more intuitive version of the working of an SVM, which however does not reflect their entire complexity. When $C$ is very large then the optimization process declared in $\eqref{eq:svmcost}$ will chose the values so that the sum of the cost of all examples is $=0$
\[\min_\theta \overbrace{C}^{\gg 0} \underbrace{\sum_{i=1}^m \left[y^{(i)} \text{ Cost}_1(\theta^Tx^{(i)}) + (1-y^{(i)}) \text{ Cost}_0(\theta^Tx^{(i)}) \right]}_{=0} + \frac{1}{2} \sum_{j=0}^n\theta_j^2\]So our optimization problem becomes
\[\begin{align} &\min_\theta C \cdot 0 + \frac{1}{2} \sum_{j=1}^n \theta_j^2 \label{eq:objectfun} \tag{3} \\ &\mathrm{s.t.} \begin {cases} \theta^Tx^{(i)}\geq & 1 & \mathrm{if} \; y^{(i)}=1 \\ \theta^Tx^{(i)}\leq &-1 & \mathrm{if} \; y^{(i)}=0 \\ \end{cases} \label{eq:constraints} \tag{4} \end{align}\]When solving this opimization problem you obtain a very interesting decision boundary. Let’s take a training set like that in Figure 19. This data is linearly separable and multiple decision boundary would separate positive and negative examples perfectly (panel A). But none of those, while minimizing the cost function, look like sensible choices, since the data hints at a pattern that is not picked up by those decision boundaries.
An SVM instead would set its decision boundary as in panel B (black line). In order to achieve that decision boundary, the SVM tries to maximize the distance between the closest points to the decision boundary itself: it tries to maximize its margins.
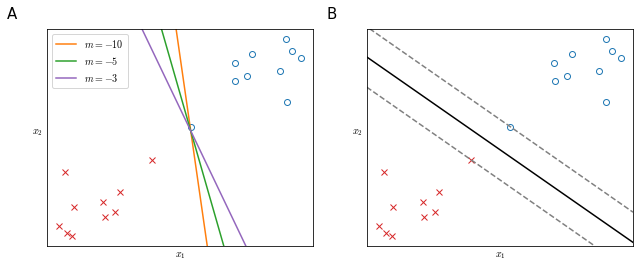
The SVM tries to separate the data with the largest margin possible, for this reason the SVM is sometimes called large margin classifier.
Large margin classifiers are not very robust to outliers and to be fair, SVMs are a bit more sophisticated and robust than the simple concept of large margin classifier explained above. SVM behaves like large margin classifier only when $C$ is very large ($\equiv \lambda$ is very small, since $C \approx \frac{1}{\lambda}$), in other words when there is no regularization. However this is a useful way to convey an intuition of how SVMs work.
Large margin classification - mathematics
In order to understand how the decision boundary is defined in a SVM we are going to adopt a set of simplifications:
- $\theta_0=0$
- number of features $n=2$
We can now rewrite $\eqref{eq:objectfun}$ as:
\[\begin{align} \min_\theta \frac{1}{2} \sum_{j=1}^n \theta^2_j & = \frac{1}{2} \left(\theta_1^2+\theta_2^2 \right) \\ &= \frac{1}{2} \left( \sqrt{\theta_1^2+\theta_2^2} \right)^2 \\ &= \frac{1}{2} \cdot \left \| \theta \right \|^2 \end{align}\]where the term $\sqrt{\theta_1^2+\theta_2^2}$ is equal to the module of the vector $\theta = [ \theta_0, \theta_1 , \theta_2 ]$. So in this case the SVM is minimizing the square norm or length of the parameter vector $\theta$.
Now let’s look at the $\theta^Tx$ terms in $\eqref{eq:objectfun}$: The training example $x^{(i)} = [x_1, x_2]$ is a vector from the origin $(0, 0)$ and the same goes for the parameter vector $[\theta_1, \theta_2]$. So we can calculate $\theta^Tx$ as the inner product of $\theta$ and $x^{(i)}$
\[\begin{align} \left \langle \theta, x^{(i)} \right \rangle &= \theta^Tx^{(i)} \\ & = p^{(i)} \cdot \| \theta \| \label {eq:innerproj} \tag{5} \\ & = \theta_1x_1^{(i)} + \theta_2x_2^{(i)} \label {eq:innerdot} \tag{6} \\ \end{align}\]where $p^{(i)}$ is the projection of $x^{(i)}$ on $\theta$ as shown in Figure 20. $\eqref{eq:innerproj}$ and $\eqref{eq:innerdot}$ are equivalent and equally valid ways to calculate $\theta^Tx$: $\eqref{eq:innerproj}$ is the inner product $\langle \theta, x^{(i)} \rangle$ and $\eqref{eq:innerdot}$ is the vector multiplication $\theta \times x^{(i)}$.
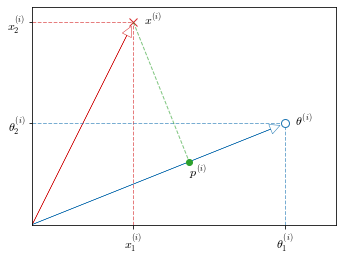
This means that we can express the constraints defined in $\eqref{eq:constraints}$ as:
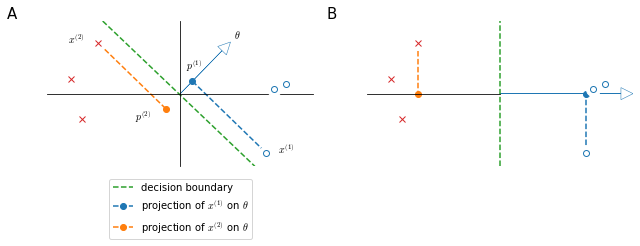
\[\begin {cases} p^{(i)} \cdot \| \theta \| \geq & 1 & \mathrm{if} \; y^{(i)}=1 \\ p^{(i)} \cdot \| \theta \| \leq &-1 & \mathrm{if} \; y^{(i)}=0 \\ \end{cases} \label{eq:constraintsproj} \tag{7}\]Now let’s see how this reflects on the decision boundary selection in a SVM. Let’s take the very simple example depicted in Figure 21.
In panel A, the decision boundary is not very good because it’s very close to the training examples: it has small margins. Let’s see why the SVM will not chose this: (it can be shown that) the parameter vector $\theta$ is orthogonal to the decision boundary and starts at origin simply because we chose to set $\theta_0=0$. If we look at the projections of $x^{(1)}, x^{(2)}$ on $\theta : p^{(1)},p^{(2)}$ we will see that they are pretty small numbers, as $x^{(1)}$ and $x^{(2)}$ are close to the decision boundary. Given $\eqref{eq:constraintsproj}$, in order to have $p^{(i)} \cdot | \theta | \geq 1$, if $p^{(i)}$ is small then $\cdot | \theta |$ must be large, but since $\eqref{eq:objectfun}$, this is not the wanted direction for $| \theta |$.
In panel B the decision boundary maximizes the margins $p^{(1)},p^{(2)}$, which in turn has the effect of reducing the size of $| \theta |$ and bringing the algorithm closer to the optimization objective.
Multi-class classification
Many SVM packages already have built-in modules for multi-class classification. Otherwise, SVMs are entirely compatible with the one-vs-all strategy that we have seen before used with logistic regression.
Briefly, the method consists in training $K$ SVMs, each one needs to distinguish $y=i$ from the rest for $y = 1, 2, \ldots, K$, by obtaining $K$ parameter vectors $\theta^{(1)}, \ldots, \theta^{(K)}$. We would then run all algorithms and just pick the class $i$ with the largest $\left( \theta^{(i)}\right)^Tx$