Unsupervised learning
When describing unsupervised learning it is useful to define it compared to supervised learning. In supervised learning what we do can be summarized as: given a set of labels, fit an hypothesis that describe the data. In contrast in unsupervised learning we don’t have any label (Figure 4)
The training set in an unsupervised learning problem is in the form
\[\left \{ x^{(1)}, x^{(2)}, x^{(3)}, \ldots, x^{(m)} \right \}\]The objective of unsupervised learning is for the algorithm to find some structure in the data.
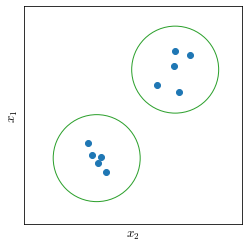
For example a structure that we can find in data points represented in Figure 26 is that the points are grouped in two clusters. This would be called a clustering algorithm
K-means clustering
In Clustering we want an algorithm to group our data into coherent subgroups.K-means algorithm is by far the most popular and widely used clustering algorithm.
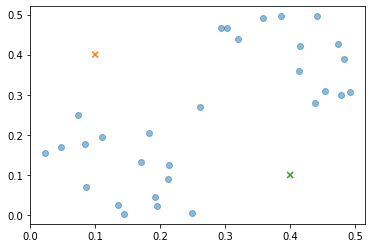
Suppose we have an unlabeled dataset and we want to apply the K-means algorithm to find if there is any structure in it. What the K-means algorithm does is first initialize random points called the centroids. In Figure 27 we can see two centroids because we want to group the data in two clusters.
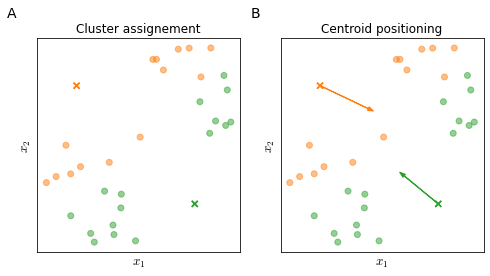
K-means is an iterative algorithm; each iteration is composed of two steps shown in Figure 28
-
Cluster assignment assign each training example $x^{(i)}$ to the closest cluster centroid
-
Centroid positioning move the centroids on the average coordinates of the points assigned to that centroid
Iterations stop when the centroids position does not change any further.
More formally, the K-means algorithm takes as input:
- The number of clusters $K$
- A training set $\left \lbrace x^{(1)}, x^{(2)}, x^{(3)}, \ldots, x^{(m)} \right \rbrace$
where $x \in \mathbb{R}^n$ since by convention $x_0=1$ is dropped.
Then the algorithm works by
-
randomly initializing $K$ clusters centroids ${ \mu_1, \mu_2, \ldots, \mu_K } \in \mathbb{R}^n$
-
Repeat until convergence
A. cluster assignment: assign each training example to its closest centroid
\[c^{(i)} := \min_k \| x^{(i)} - \mu_k \|^2\]B. centroid positioning: move each centroid to the average coordinates of its assigned training examples
\[\mu_k = \frac{1}{m^{(c=k)}} [x^{(c_1)}, x^{(c_2)}, \ldots] \in \mathbb{R}^n\]
If a centroid has no points assigned it can be:
- eliminated, you will then have $K-1$ centroids
- randomly reassigned (less common)
K-means for non-separated clusters
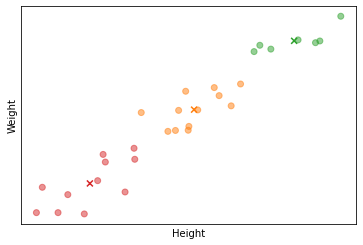
Until now we have seen the K-means algorithm applied to data were clusters are well separated but sometimes K-means is also applied to non separated clusters. In the example shown in the figure below we see the height and weight of a set of people. In this case we might be interested in grouping these people in three T-shirt sizes (three clusters).
K-means optimization objective
Alike to supervised learning also K-means algorithm has an optimization objective. Given
- $c^{(i)}$ index of cluster to which the example $x^{(i)}$ is assigned
- $\mu_k$ centroid $k$
- $\mu_{c^{(i)}}$ centroid of the cluster to which example $x^{(i)}$ is assigned
The cost function $J$ (sometimes called the Distortion cost function) is
\[J\left( c^{(1)}, \ldots, c^{(m)}, m_1, \mu_1, \ldots, \mu_K, \right) = \frac{1}{m} \sum^m_{i=1} \left \| x^{(i)} - \mu_{c^{(i)}} \right \|^2\]and the optimization objective is
\[\min_{c^{(1)}, \ldots, c^{(m)}, \\ \mu_1, \ldots, \mu_K} J\left( c^{(1)}, \ldots, c^{(m)}, m_1, \ldots, \mu_K, \right)\]Random Initialization
Correct random initialization prevent the optimization algorithm to stop in local optima. There are many possible ways to randomly initialize the cluster centroids, however there is one method that usually works better than the other options.
First, we should have $K < m$. Once defined $K$, we randomly pick $K$ training examples and set $\mu_1, \ldots, \mu_K$ equal to these $K$ selected examples.
While the above method reduces the chances of falling in local optima there is still a probability of it happening. A way to prevent that, is to run random initialization and K-means optimization multiple times and then pick the clustering that gave the lowest cost.
Do notice that the need for multiple random initializations reduce while $K$ increases.
Number of clusters
The best method to choose the number of clusters is usually picking it manually based on considerations or visual inspection of data.
One of the reasons why it is difficult to choose the number of cluster is because it is genuinely ambiguous how many clusters there actually are in a data set.
If no particular requirement is specified (in Figure 29 we wanted exactly three clusters, for the three sizes of t-shirts S, M, L), a method that is sometimes used is known as the elbow method.
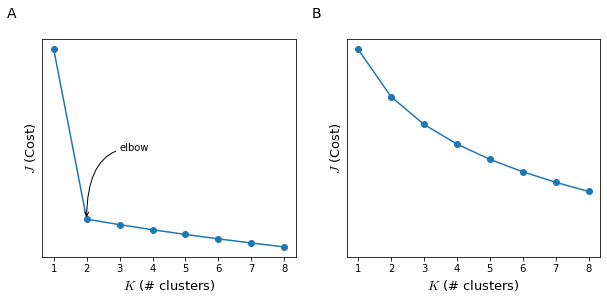
When using this method we will calculate the cost $J$ as a function of the number of clusters $K$ (Figure 30) and try to identify a region where there is an elbow (there is a sharp change of the direction of the $J$ by further increasing $K$). such elbow is present in the plot (panel A) than we can select the $K$ at which we have the hinge of the elbow. However usually the $J$ by $K$ function is much less clear (panel B) and it is not suitable to identify an optimal $K$.