Optimization and speeding learning up
In early days of machine learning, a lot of concern revolved around the idea of the optimization process getting stuck in local optima of the target function. This was due to an intuitive representation of high-dimensional space that reflected our experience with low-dimensional space. In this intuition, highly dimensional space has many crevices of local optima (Figure 54, panel B). It is expected that most points in highly-dimensional feature space are saddle points.
The reason why finding local optima is very unlikely in highly dimensional space is because for a local minimum to be such, the local values of the function must be concave in all dimensions. Since a function (locally) can either be concave or convex (2 degrees of freedom), this means that the probability of each point to be in a local minimum is $2^{-d}$, where $d$ is the number of dimensions. With many thousands of dimensions, as often happens in deep learning, this probability is extremely small. It is instead much more likely that some dimensions will be locally concave and some locally convex, thus giving a saddle point.
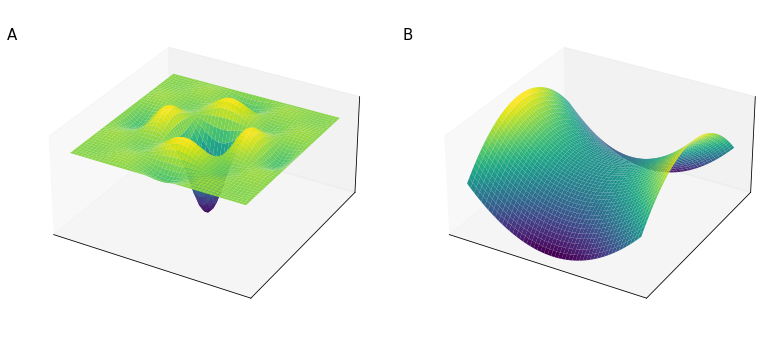
In this highly dimensional space, what turns out to be a serious problem are instead plateau (Figure 55), a zone of a multi-dimensional function where the derivatives are 0 or close to 0, slowing down the learning process.
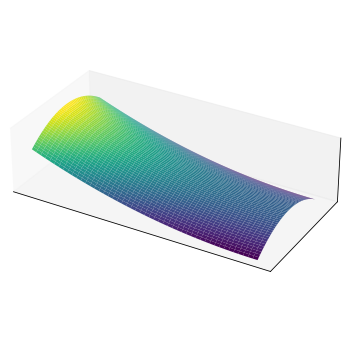
This is why many optimization techniques of the deep-learning era are focused on speeding-up the learning process, which due to the high-dimensional space from which deep neural network take advantage, tends to be extremely slow.
Training set normalization
Training set normalization is a technique that speeds up the learning process. Typically, input features come in range that differ of some order of magnitude. One feature might come in range $[0, 1000]$ and another in range $[0, 1]$.
Difference in the scale of input features might make training very slow and for this reason input features are usually normalized. In Figure 56 the effect of the two steps of mean normalization are shown.
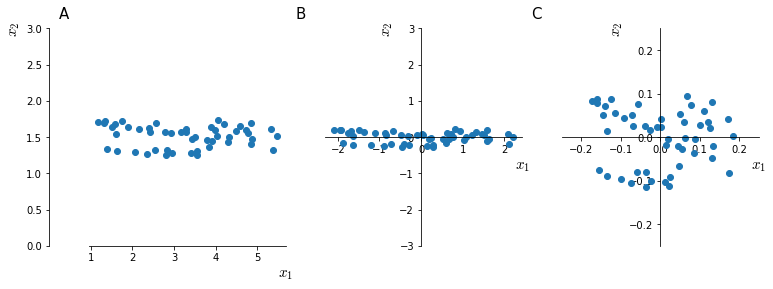
.
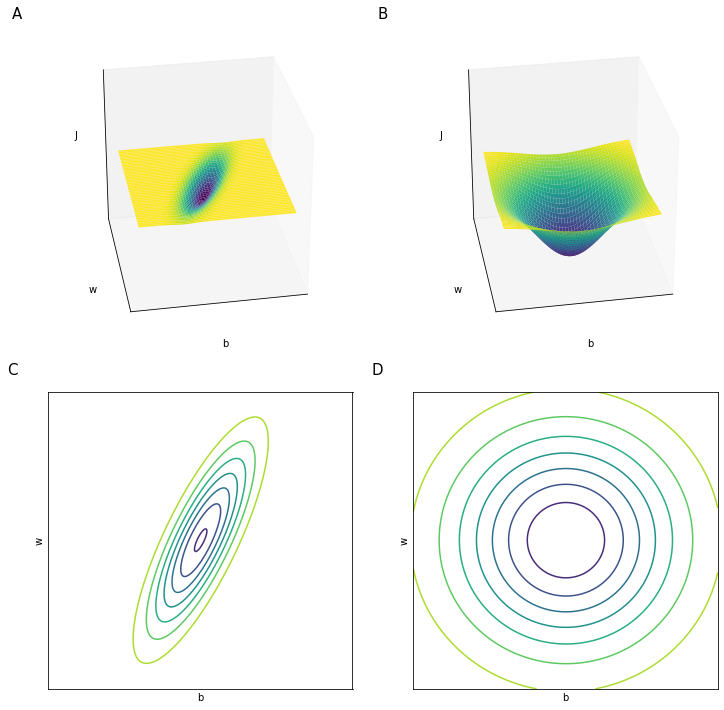
To intuitively understand why mean normalization speeds up training the values, Figure 57 shown a simplified view of how the space of the values assumed by the cost function $J$ change with un-normalized (panels A,C) and normalized inputs (panels B,D)
Vanishing or Exploding gradients
Under some circumstances it may happen, especially in very deep neural networks, that gradients (derivatives) assume very small (vanishing) or big (exploding) values.
This problem can be drastically reduced through a careful choice of the random weight initialization.
Suppose we have a very deep network as in the Figure 58. This network has many hidden layers and consequently a series of parameters matrices $(w^{[1]}, w^{[2]}, \dots w^{[L]})$. For the sake of simplicity let’s say that this network has linear activation function ($g(z) = z$) and that $b^{[l]}=0$

For this network
\[\begin{aligned} \hat{y} = w^{[L]} \cdot w^{[L-1]} \cdot w^{[L-2]} \cdot \ldots \cdot w^{[2]} \cdot w^{[1]} \cdot x \\ z^{[1]} = w^{[1]}x \\ a^{[1]} = g(z^{[1]}) = z^{[1]} \\ a^{[2]} = g(z^{[2]}) = g(w^{[2]}a^{[1]}) \\ a^{[2]} = g(z^{[2]}) = g(w^{[2]}w^{[1]}x) \\ \cdots \end{aligned}\]Suppose that each of our weight matrices $w^{[l]}$ is
\[w^{[l]} = \begin{bmatrix} 1.5 & 0 \\ 0 & 1.5 \end{bmatrix} \qquad \to \qquad \hat{y}= \begin{bmatrix} 1.5 & 0 \\ 0 & 1.5 \end{bmatrix}^{L-1}x\]$\hat{y}$ will increase exponentially with $1.5^L$. This implies that for large values of $L$ the value of $\hat{y}$ will explode. Conversely the value of $\hat{y}$ will vanish for weights $w^{[l]} < I$ (where $I$ is the identity matrix).
In general
\[\hat{y} \begin{cases} w^{[l]} > I \qquad \to \text{explode} \\ w^{[l]} < I \qquad \to \text{vanish} \end{cases}\]And while we made this argument for the activation values we can make a similar argument for the gradients
Correct weight initialization to attenuate gradient derive
Let’s focus on a single neuron with 4 input features
For the network in Figure 59
\[z = w_1x_1 + w_2x_2 + \ldots + w_nx_n\]So the larger $n$ is, the smaller we want to set $w_i$ in order to prevent gradient explosion. It would be ideal to set the variance of $w_i$ to be inversely proportional to $n$
\[\sigma^2(w_i) = \frac{1}{n}\]So, in order to set the variance for random variables drawn from a Gaussian distribution we would write our weights matrix as:
nx = 4
np.random.randn(1, nx)*np.sqrt(1/nx)
array([[ 0.23828286, 0.3988794 , 0.3639038 , -0.00712072]])
where randn() draws from a Gaussian distribution and the term can vary depending on the activation function used and implementation details:
For a ReLU activation function:
\[\sqrt{\frac{2}{n^{[l-1]}}}\]For $\tanh$
\[\sqrt{\frac{1}{n^{[l-1]}}}\]Or sometimes this different implementation, also called Xavier initialization:
\[\sqrt{\frac{2}{n^{[l-1]}+1}}\]