Hyperparameter tuning
Tuning process
How to organize your hyperparameters tuning process. In deep-learning you come across many hyper-parameters: We have seen:
- the learning rate $\alpha$ (if you are using a constant learning rate)
- the momentum parameter $\beta$
- the parameters $\beta_1, \beta_2, \epsilon$ if using ADAM optimization
- the number of hidden layers
- the number of hidden units in each layer
- the number of epochs
- the learning rate decay system and its parameter and possibly its parameter $k$
- the mini-batch size $t$
In many cases, if sorted by their importance the list would be:
- The single most important hyperparameter in almost all situations is the learning rate $\alpha$.
- Second in importance come
- the momentum parameter $\beta$, for which $0.9$ is found to be be a good default parameter.
- the the mini-batch size
- the number of hidden units in layers
- Third in importance come
- the number of layers (that can sometime make a huge difference)
- the learning rate decay
- When using an ADAM optimization algorithm usually its parameters are never tuned and the default are kept ($0.9, 0.999, 10^{-8}$)
However it is very difficult to give a general rule for the importance of hyperparameters and each model tend to behave differently.
Approaches to hyperparameter tuning
When approaching hyperparameter tuning there two choices, which are based on the amount of computational power available and the complexity (in terms of size of the network and training data) of the model:
-
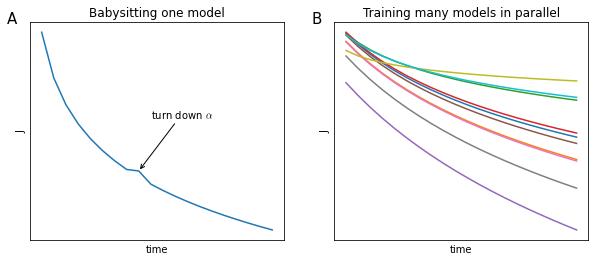
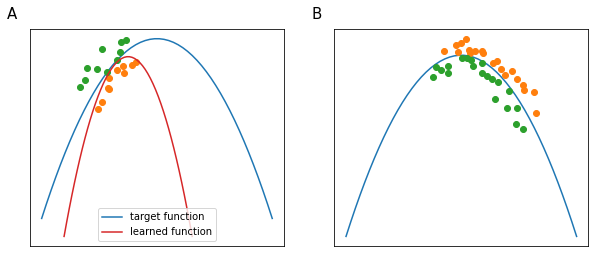
If computational resources are scarce relatively to the complexity of the model, then one tends to babysit one model. A single model is trained and its hyperparameters are tuned day by day based on the progress of the training (Figure 66, panel A).
-
If computational resources are abundant, it is always better to train many models in parallel, each with a different set of hyperparameters (Figure 66, panel B).
Hyperparameter exploration
In early days of machine learning, practitioners would sample the space of hyperparameters systematically, by testing combinations of intervals of hyperparameters (Figure 67, panel B), since it is almost impossible to know in advance which hyperparameter will have more impact on the model, but at the same time some hyperparameters tend to be much more important than others
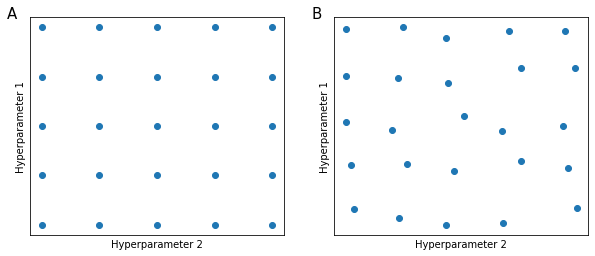
This is done because when sampling the hyperparameter space as in Figure 67 panel B, is a different set of Hyperparameters 1 and 2.
Scale of hyperparameters
Choosing hyperparameters at random doesn’t mean that they all need to be randomly picked from a uniform distribution, each parameter should have the appropriate scale (Figure 68). The number of hidden layers $n^{[l]}$ can be sampled from a uniform random distribution between 50 and 100, but for the number of hidden layers $L$ it is more sensible to maybe explore all the values between 2 and 4. For the learning rate $\alpha$ a uniform random sampling would waste many computational resources since we want to sample a much bigger range [0.0001, 1], and a logarithmic random sampling would be more appropriate.

.
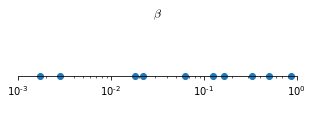
A different strategy is usually employed when sampling for the hyperparameters for exponentially weighted averages. Common values for $\beta$ range from 0.9 to 0.999 but a linear sampling in this range would be extremely inefficient, since the effect of small changes in $\beta$ is almost null when $\beta \approx 0.9$ and very big when $\beta \approx 0.999$
\[\begin{aligned} & \beta = 0.9000 \to \frac{1}{1-\beta}\approx 10 \qquad & \to & \qquad \beta = 0.9005 \to \frac{1}{1-\beta}\approx 10 \\ \\ & \beta = 0.9990 \to \frac{1}{1-\beta}\approx 1000 \qquad & \to &\qquad \beta = 0.9995 \to \frac{1}{1-\beta}\approx 2000 \\ \end{aligned}\]For this reason, usually instead of $\beta$, we sample $\beta - 1$ in a logarithmic random distribution in the range $\left[10^{-1}, 10^{-3} \right]$ (Figure 69)
Batch Normalization
Batch normalization is a technique that makes the search of hyperparameters much easier because it makes a neural network much more robust to different choice of hyperparameters, increasing the range of hyperparameters that work well with a model and makes the learning speed of deep neural network much faster.
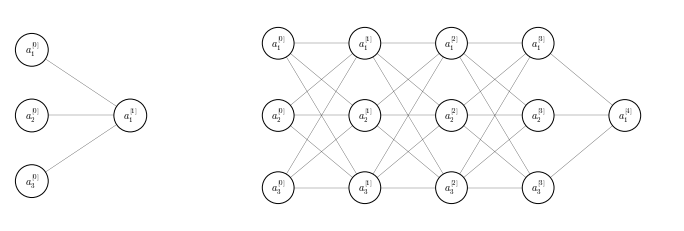
We have seen that when training a model, normalizing the input features can speed up training (ML28). Normalizing the input feature values works in a shallow neural network, but in a deep neural network we no longer have just input feature, but also a series of activation values for each layer (Figure 70).
Implementing Batch Norm
In batch normalization, we normalize values at each layer $l$ in order to train $w^{[l+1]}, b^{[l+1]}$ faster. There is some debate within the machine learning community about whether values should be normalized before ($z^{[l]}$) or after ($a^{[l]}$) applying the activation function. In practice normalizing $z^{[l]}$ is much more frequent.
Given some intermediate value in a neural network for a layer $l$, ($z^{(i)[l]}$) in the range from 1 to $m$, $z^{(1)[l]}, \dots, z^{(m)[l]}$
\[\begin{split} & \mu = \frac{1}{m} \sum_i z^{[l](i)} \\ &\sigma^2 = \frac{1}{m} \sum_i(z^{[l](i)}-\mu)^2 \\ &z^{[l](i)}_\text{norm} = \frac{z^{[l](i)} - \mu}{\sqrt{\sigma^2+\epsilon}} \end{split}\]This way each of the intermediate values $z^{(i)[l]}$ will have mean 0 and standard deviation 1. However, for some hidden layers it makes sense that the intermediate levels assume another distribution (forcing them to the normal standard distribution would make the hidden units to always behave linearly for a sigmoid activation function, see Figure 50), so in order to correct that we compute
\[\tilde{z}^{[l](i)} = \gamma z^{[l](i)}_\text{norm} + \beta\]where $\gamma$ and $\beta$ are learnable parameters of the model and get updated during the optimization process. The effect of these parameters is to set the mean and variance to whatever value is more appropriate, respect to data. In fact, we have
\[\begin{split} & \gamma = \sqrt{\sigma^2 + \epsilon}\\ & \beta = \mu \\ \end{split} \qquad \to \qquad \tilde{z}^{[l](i)} = z^{[l](i)}\]By adjusting these parameters, we can have standardize mean and variance across one layer $l$, where the actual values of mean and variance are controlled by the learned parameters $\gamma$ and $\beta$
Fitting Batch Norm in a neural network
Suppose you have a $L$ layer neural network. The process of applying batch normalization throughout the neural network would be that depicted in Figure 71

As the other learned parameters $\beta$ and $\gamma$ are updated during the optimization, for example if using gradient descent:
\[d\beta^{[l]} \to \beta^{[l]} = \beta^{[l]} - \alpha d\beta^{[l]}\]The process in Figure 71 refers to application of batch normalization to batch gradient descent. Usually, batch normalization is applied to mini-batches, in which case the process is:

Now, $z^{[l]}$ is computed as
\[z^{[l]} = w^{[l]}a^{[l-1]}+b^{[l]}\]But since batch norm is going to first normalize $z^{[l]}$ to $\mu=0, \sigma^2=1$ and then rescale by $\beta, \gamma$. This means that whatever the value of $b$ it is going to be subtracted during the computation of the mean of the $z^{[l]}$ vector and adding any constant to all examples in a mini-batch doesn’t affect the mean.
So the actual parameter of the batch norm are $w^{[l]}, \beta^{[l]}$ and $\gamma^{[l]}$
Batch Normalization reduces covariate shift
When training a model on a training set we try to make the model generalize to be robust to changes in the distribution of data (Figure 72). The idea of data distribution changing is called covariate shift. Usually if the distribution of our input data changes we may need to retrain our algorithm, even if the target function remains unchanged.
In a deep neural network like that in Figure 70 parameters $w^{[4]}, b^{[4]}$ map the values of $a^{[3]}$ to $a^{[l]}$ as to minimize the cost function $J$. However the values of $a^{[3]}$ are in turn changing during the next epoch (due to the effect of the update of $w^{[3]}, b^{[3]}$) and the distribution $a^{[3]}$ will change. So, from the perspective of $l=3$, the input values are changing all the time and so they are suffering from the problem covariate shift.
Batch norm will reduce the amount that the distribution shifts, because while the values will change, their mean and variance will remain the same. So in other words batch norm limits the amount of which varying the values of the early layers affect the distribution of later layers.
In some sense batch norm reduces the coupling of what each layer is modeling, rendering each layer more independent in what they are learning.
Batch norm regularization side-effect
Since each mini-batch is scaled by the mean and variance computed on just that mini-batch, batch norm adds some noise to the values $z^{[l]}$ within that mini-batch. Similarly to dropout it adds some noise to each hidden layer’s activation values.
This has a slight regularization effect (by no mean as powerful as dropout dropout), the bigger the mini-batch size, the smaller the regularization effect. can be used together with batch norm to add a real regularization step.